Hacking together a Job Runner using Supabase Edge Functions
 Postgres
PostgresIf you're not familiar with Supabase, it's a collection of backend services (Postgres, PostgREST auth service, S3 storage, function runtime) that you can develop against locally and then deploy to production.
The Supabase team have also spent time making each of these parts complement each other, and since they're stitching together different open source projects this is seriously impressive. They also have in-depth documentation and examples, and the dashboard is top notch.
ℹ️ What makes Supabase so useful?
For example, items uploaded to the storage service are accessible via the database. The auth service is also hooked directly into the database, with convenience functions to wire up user permissions to the authenticated users. This means you can enforce object storage access permissions (using Postgres Row-Level Security) all the way through the stack via the database:
create policy "Individual user Access"
on storage.objects for select
to authenticated
using ( (select auth.uid()) = owner_id::uuid );
Additionally, the database is presented via a REST interface using PostgREST. With the aforementioned RLS policies, this gives you a permission-controlled API that you can auto-generate clients for. That means a React application can have a type-hinted, robustly authorized interface to the database – this makes it easier to build systems that are both secure and have a nice developer experience.
This is powerful stuff, and not necessarily easy to grok, but ultimately you're just learning how to use Postgres, so the knowledge is portable.
Anyway, this is all great stuff, but at some point I wanted to be able to run a bunch of asynchronous work in the background.
#Background jobs
What you need out of a background job runner varies wildly. Supabase provides some helpful primitives around this that are enough to get started with – you can fire off Edge Functions after a request and set them to process as Background Tasks, and you can use pg_cron to run them on a schedule.
If you just want to run a few static tasks regularly with Supabase, send emails, or fire off an API request after a user action, it's pretty straight forward. There are also ways to set up triggers, and fire webhooks on database events.
What I needed was a system where I could regularly run tasks in the context of a user – AI agents running on behalf of the user, checking third party services for new information, etc. Something which might take a while to run, or is part of automation that will trigger another action, maybe alert a customer.
I wanted to be able to queue up sometimes thousands of jobs to run – this would help me stagger their execution so that I wasn't overwhelming either the Supabase Edge Function dispatcher or my own APIs.
It was also important to me to keep the overall infrastructure stack as lean as possible, because I was deploying a stack per-company to keep resources isolated, as well as geographically proximate to the people using it.
There are, of course, third-party job runner systems like Inngest, Hatchet, trigger, or Temporal, some of which are open source, have UIs, a local dev system, and I'm sure lots of other useful features. But this is a class of problem that ranges from "Google Calendar reminder for me to run a script manually on Sundays" to "distributed MapReduce operation across a Kubernetes cluster" – you'll want something that suits your own circumstances.
#Cobbling together a job runner
The Supabase Edge runtime environment takes the form of Deno functions triggered via HTTP, and authorized using JWT. They are normal HTTP API endpoints, you can send payloads to them, stream results and return status codes.
Supabase also provides a PostgreSQL database with a variety of Postgres extensions installed, including pg_cron and pg_net.
With those pieces in place, we have the primitives for a system that can:
- store a list of jobs and config
- run Typescript functions (with some resource limits, see Caveats)
- run tasks on a schedule
- execute and evaluate the success of functions called over HTTP
- propagate user authorization context into the edge functions
- be permission controlled via RLS
The basic idea is that you write your jobs as Supabase Edge Functions, and you control when they're executed and what data they are passed using the database. The name of the job should map directly to the name of the Supabase Edge Function associated with it. pg_cron is used to pick up new jobs and clean up old ones.
Because it's implemented in the database, you can use it via Supabase's dashboard too, so if you want to see what jobs are running, fix them or run them manually, you can do it easily via the UI:
Supabase's dashboard gives you the option to impersonate a user and run queries as them, which is immensely helpful when you have a lot of business logic and permissions encoded in SQL.
I found the only public endpoints I needed were some functions to queue and dequeue tasks on behalf of the user, everything else was internal to the job system and rarely needs to be used directly.
So I ended up with a system where a job is queued from the code like:
const { error } = await supabase.rpc(
"queue_job",
{
_job_name: "example-job",
_request_body: {
"data": true
}
},
);
Or more frequently as part of a database trigger:
CREATE OR REPLACE FUNCTION private.queue_directory_agent_for_meeting_trigger()
RETURNS TRIGGER AS $$
DECLARE
existing_run UUID;
BEGIN
-- Check if an agent run is already pending/running for this meeting
SELECT id INTO existing_run
FROM public.agent_run
WHERE request_body ->> 'meetingId' = NEW.meeting_id::text
AND agent_name = 'directory-agent'
AND state IN ('pending', 'running');
IF existing_run IS NULL THEN
-- No pending/running run exists; queue the agent for the meeting
PERFORM public.queue_job(
'directory-agent',
jsonb_build_object('meetingId', NEW.meeting_id)
);
END IF;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE OR REPLACE TRIGGER queue_directory_agent_after_insert_update
AFTER INSERT OR UPDATE ON user_meetings
FOR EACH ROW
EXECUTE FUNCTION private.queue_directory_agent_for_meeting_trigger();
That then gets picked up by the job system, which then runs the task via Supabase Edge Functions.
There is a lot of code on this page – feel free to copy and paste it into an LLM to ask questions and customize. You can find all the code in this Github repository.
#Assumptions
This setup assumes you want to run a job in the permission context of each user. There's nothing to stop you having global jobs, I just didn't need/want them so they're not accounted for in this set up.
Every Edge Function needs to accept and respond with headers it receives from the job runner for tracking purposes (X-Job and X-Correlation-ID). I originally tried doing this with internal request IDs for pg_net, but they're just integers that are reset when the database is restarted, so not reliable.
#Some initial configuration
I'm making use of a few extensions and a private schema:
CREATE EXTENSION IF NOT EXISTS pg_cron WITH SCHEMA extensions;
CREATE EXTENSION IF NOT EXISTS pgjwt WITH SCHEMA extensions;
CREATE EXTENSION IF NOT EXISTS pg_net WITH SCHEMA extensions;
CREATE SCHEMA private;
And the supabase_url() helper function is something I picked up from example projects. It's useful for getting the URL for your REST endpoints within the database (part of how the system will execute Edge Functions):
CREATE FUNCTION supabase_url()
RETURNS TEXT
LANGUAGE plpgsql
SECURITY DEFINER
AS $$
DECLARE
secret_value TEXT;
BEGIN
SELECT decrypted_secret
INTO secret_value
FROM vault.decrypted_secrets
WHERE name = 'supabase_url';
RETURN secret_value;
END;
$$;
You may have noticed this pulls a Supabase Vault secret. This is really just somewhere to keep a variable for the project URL. You can configure this locally with a statement in your seed.sql file like:
DO $$
DECLARE
secret_value TEXT;
BEGIN
-- Check if the secret already exists
SELECT decrypted_secret INTO secret_value
FROM vault.decrypted_secrets
WHERE name = 'supabase_url';
-- If secret_value is null, it means the secret does not exist,
-- so create it
IF secret_value IS NULL THEN
PERFORM vault.create_secret(
'http://api.supabase.internal:8000',
'supabase_url');
END IF;
END $$;
But if you're deploying this to production, you'll want to copy your supabase URL from the API → API Settings page:
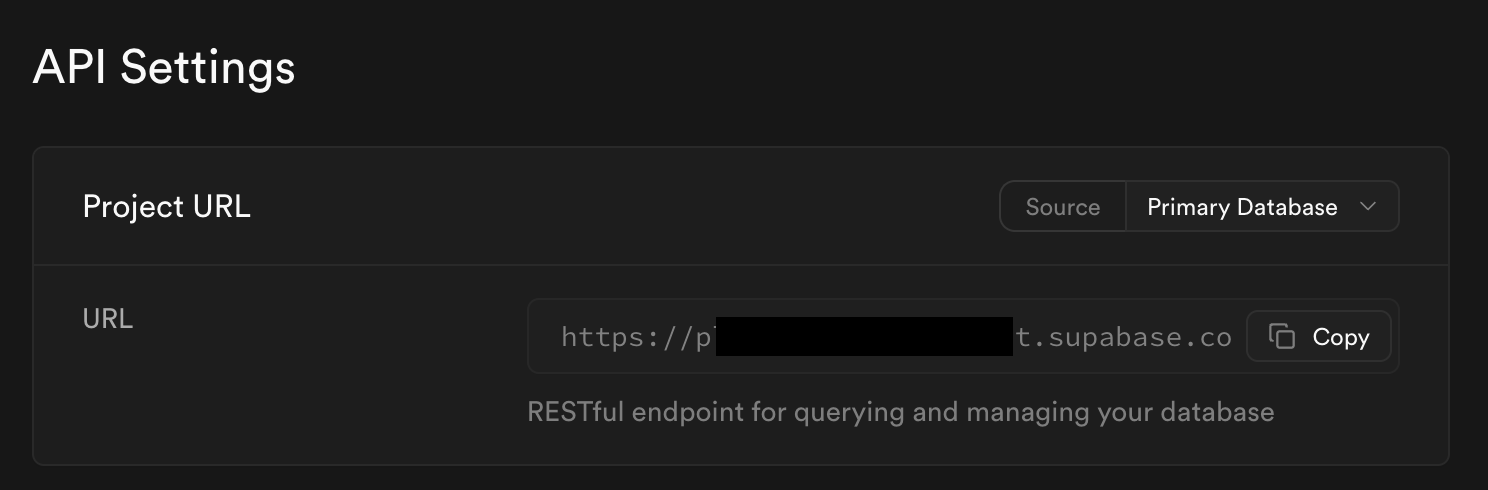
Into Vault:
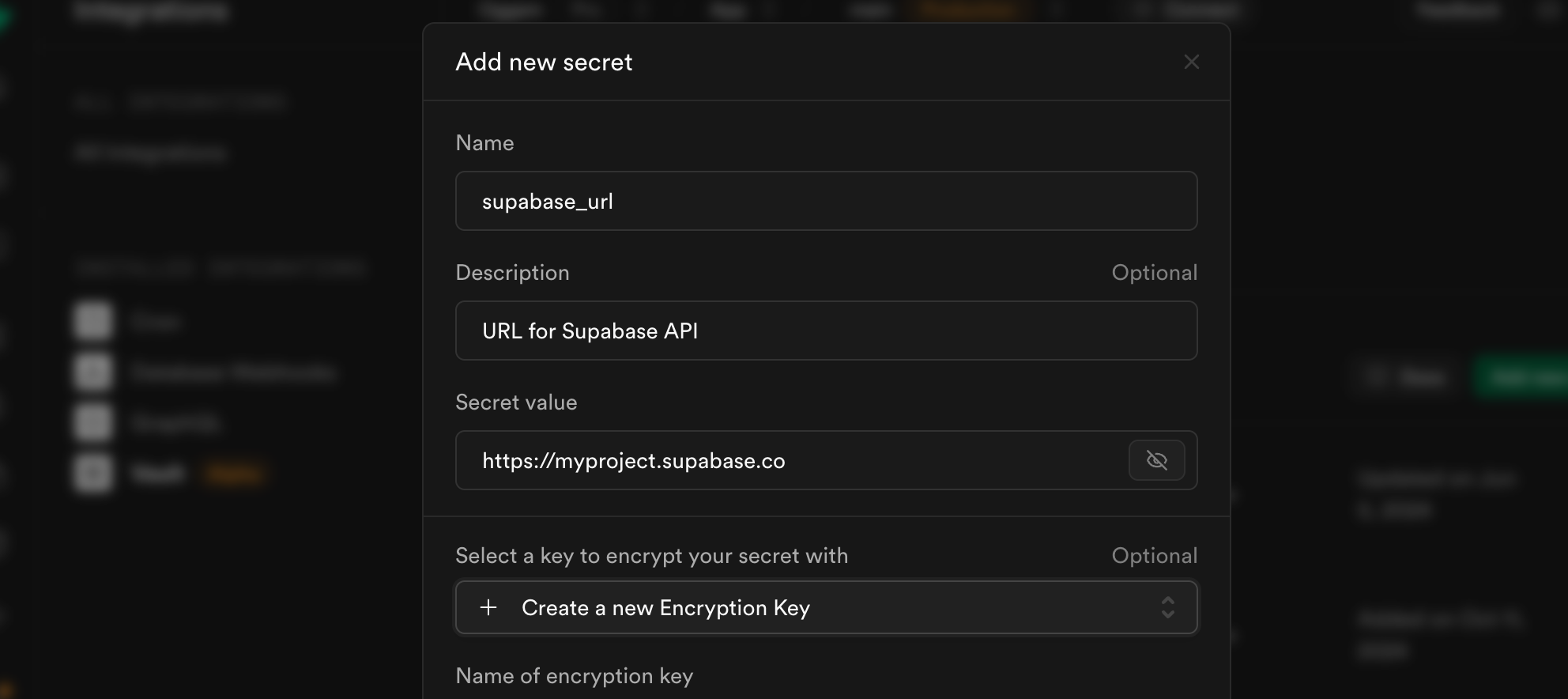
Due to security changes in November 2024, we also need a function for retrieving the JWT secret:
CREATE FUNCTION private.jwt_secret()
RETURNS TEXT
LANGUAGE plpgsql
SECURITY DEFINER
AS $$
DECLARE
secret_value TEXT;
BEGIN
SELECT decrypted_secret
INTO secret_value
FROM vault.decrypted_secrets
WHERE name = 'app.jwt_secret';
RETURN secret_value;
END;
$$;
Again, you'll need to populate this secret value via the Vault interface. You can find the appropriate a few settings below the Project URL:
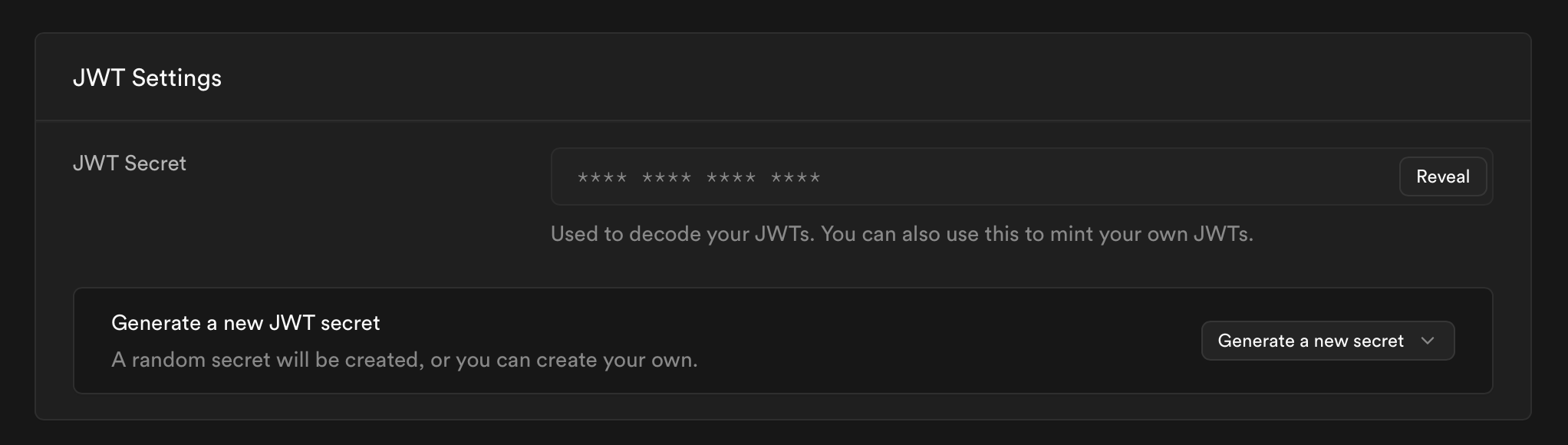
#Tables
I've defined three tables, job, job_config, and job_logs. Everything else is private functions for managing the state in those tables and in pg_net, and defining pg_cron jobs.
#job
This is the execution information for a specific job. Most of the column names are self-explanatory, but just to highlight that request_body is what will be send as a JSON payload to the defined Supabase Edge Function.
An RLS policy allows the user CRUD operations on the table for their own jobs.
Indexes are included which might be useful by the time your job system has been running for a while, but at the same time you might be just as well deleting older completed jobs.
CREATE TABLE job (
id UUID PRIMARY KEY DEFAULT uuid_generate_v4(),
user_id UUID NOT NULL REFERENCES auth.users(id) ON DELETE CASCADE,
job_name TEXT NOT NULL CHECK (TRIM(job_name) <> ''),
request_body JSONB,
state TEXT NOT NULL DEFAULT 'pending',
retries INT DEFAULT 0,
max_retries INT DEFAULT 3,
created_at TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
updated_at TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
last_run_at TIMESTAMP WITH TIME ZONE,
next_run_at TIMESTAMP WITH TIME ZONE,
locked_at TIMESTAMP WITH TIME ZONE,
CONSTRAINT chk_valid_state CHECK (state IN (
'pending', 'running', 'completed', 'failed', 'canceled'
))
);
ALTER TABLE job ENABLE ROW LEVEL SECURITY;
CREATE POLICY "Users can manage their own job runs"
ON job FOR ALL TO authenticated USING (
(SELECT auth.uid()) = user_id
) WITH CHECK (
(select auth.uid()) = user_id
);
CREATE INDEX idx_job_user_jobname ON job(user_id, job_name);
CREATE INDEX idx_job_state ON job(state);
CREATE INDEX idx_job_locked_at ON job(locked_at);
CREATE INDEX idx_job_pending ON job(user_id, job_name)
WHERE state IN ('pending', 'running');
#job_config
This is used to control configuration for all jobs with a specific name, in this case enabling/disabling the jobs and controlling the concurrency. RLS is enabled, but no policy is added, meaning it is not directly accessible to users.
CREATE TABLE job_config (
job_name TEXT PRIMARY KEY,
concurrency_limit INT DEFAULT 1 CHECK (concurrency_limit > 0),
enabled BOOLEAN NOT NULL
);
ALTER TABLE job_config ENABLE ROW LEVEL SECURITY;
#job_logs
Basic job logging. This could be made more useful – what it does at the moment is log when a job starts and finishes. RLS policy for user CRUD also included.
CREATE TABLE job_run_logs (
id UUID PRIMARY KEY DEFAULT uuid_generate_v4(),
job_run_id UUID REFERENCES job_run(id) ON DELETE NO ACTION,
log_message TEXT,
log_level TEXT NOT NULL DEFAULT 'INFO',
created_at TIMESTAMP WITH TIME ZONE DEFAULT now()
);
ALTER TABLE job_run_logs ENABLE ROW LEVEL SECURITY;
CREATE POLICY "Users can manage their own job run logs"
ON job_logs FOR ALL TO authenticated USING (
EXISTS (
SELECT 1
FROM job
WHERE job.id = job_logs.job_id
AND job.user_id = (select auth.uid())
)
) WITH CHECK (
EXISTS (
SELECT 1
FROM job
WHERE job.id = job_logs.job_id
AND job.user_id = (select auth.uid())
)
);
#Public functions
As I mentioned, there's really only two functions I needed to use on a regular basis, one to queue up a new job, and another to remove a job from the queue. You could have functions to list jobs, etc, but I found just SELECT over the table was all I needed.
-- Public methods
CREATE OR REPLACE FUNCTION public.queue_job(
_job_name TEXT,
_request_body JSONB,
_max_retries INT DEFAULT 3
)
RETURNS UUID
SET search_path = public, extensions
AS $$
DECLARE
new_job_id UUID;
BEGIN
-- Insert a new job for the current user
INSERT INTO job (user_id, job_name, request_body, max_retries)
VALUES ((select auth.uid()), _job_name, _request_body, _max_retries)
RETURNING id INTO new_job_id;
-- Log the creation of the job
PERFORM public.log_job(new_job_id, 'job run created');
-- Return the ID of the new job
RETURN new_job_id;
END;
$$ LANGUAGE plpgsql;
CREATE OR REPLACE FUNCTION public.dequeue_job(
_job_id UUID
)
RETURNS VOID
SET search_path = public, extensions
AS $$
BEGIN
-- Update the job to 'canceled' if it is still in the pending state
UPDATE job
SET state = 'canceled', updated_at = now()
WHERE id = _job_id
AND state = 'pending';
-- Log the cancellation of the job
PERFORM public.log_job(_job_id, 'job run canceled');
END;
$$ LANGUAGE plpgsql;
#Management functions
All of these are created in a schema named private, which by default has no permissions attached to it, and is not presented via the REST API. That means (without specific configuration) they are executable only by special roles like the postgres user, which is exactly what we need.
#Helper: generate a JWT for a user
This is a helper function that lets your job management system create a valid JWT token that it can use to execute Edge Functions on behalf of a user.
This is handy, and also one you have to be very careful about. You don't want to accidentally allow anyone to mint a JWT for any user via the API just by suppling the user's ID 😅
Being in the private schema should prevent this, and the user_id is a UUID (so not amenable to iterating through like integers), but just keep in mind that you probably don't want a public schema version of this function.
CREATE FUNCTION private.generate_user_jwt(
p_user_id UUID, p_user_role TEXT, p_user_email TEXT)
RETURNS TEXT
LANGUAGE plpgsql
SECURITY DEFINER
SET search_path = public, extensions
AS $$
DECLARE
jwt_token TEXT;
exp_time TIMESTAMP;
BEGIN
-- Calculate expiration time (1 hour from now)
exp_time := now() + interval '1 hour';
-- Generate the JWT
jwt_token := extensions.sign(
payload := json_build_object(
'sub', p_user_id,
'aud', p_user_role,
'role', p_user_role,
'email', p_user_email,
'iat', extract(epoch from now()),
'exp', extract(epoch from exp_time)
)::json,
secret := (select private.jwt_secret()),
algorithm := 'HS256'
);
RETURN 'Bearer ' || jwt_token;
END;
$$;
#Running jobs
These two functions handle job initialization. The http request lifecycle is managed via pg_net, the rest of the work is in checking job state and concurrency management.
CREATE FUNCTION private.run_job(
_job_id UUID,
_job_name TEXT,
_request_body JSONB,
_user_id UUID,
_role TEXT,
_email TEXT
)
RETURNS VOID
LANGUAGE plpgsql
SECURITY DEFINER
AS $$
DECLARE
timeout_milliseconds INT := 5 * 60 * 1000;
auth_header TEXT;
BEGIN
-- Generate the JWT for the current user based on their role and email
auth_header := private.generate_user_jwt(_user_id, _role, _email);
PERFORM
net.http_post(
url := supabase_url() || '/functions/v1/' || _job_name,
headers := jsonb_build_object(
'Content-Type', 'application/json',
'Authorization', auth_header,
'X-Correlation-ID', _job_id::TEXT,
'X-Job', 'true'
),
body := _request_body,
timeout_milliseconds := timeout_milliseconds
);
END;
$$;
CREATE FUNCTION private.run_jobs()
RETURNS VOID
LANGUAGE plpgsql
SECURITY DEFINER
SET search_path = public, extensions
AS $$
DECLARE
job_group RECORD;
max_concurrency INT;
running_jobs INT;
available_slots INT;
job_enabled BOOLEAN;
current_job RECORD;
BEGIN
-- Fetch all user-job pairs with pending jobs
FOR job_group IN
SELECT job.user_id, job.job_name
FROM job
WHERE job.state = 'pending'
AND job.locked_at IS NULL
AND (job.next_run_at IS NULL OR job.next_run_at <= now())
GROUP BY job.user_id, job.job_name
LOOP
-- Skip if job is disabled
SELECT enabled INTO job_enabled
FROM job_config
WHERE job_name = job_group.job_name;
IF NOT job_enabled THEN
RAISE LOG 'job %s disabled via job_config', job_group.job_name;
CONTINUE;
END IF;
-- Get the global concurrency limit for the job
SELECT concurrency_limit INTO max_concurrency
FROM job_config
WHERE job_name = job_group.job_name;
-- Default to 1 if not specified
IF max_concurrency IS NULL THEN
max_concurrency := 1;
END IF;
-- Count the number of currently running jobs for this user-job pair
SELECT COUNT(*) INTO running_jobs
FROM job
WHERE job_name = job_group.job_name
AND user_id = job_group.user_id
AND state = 'running';
-- Calculate available slots for this user-job pair
available_slots := max_concurrency - running_jobs;
IF available_slots > 0 THEN
-- Select pending jobs up to the available slots
FOR current_job IN
SELECT job.id, job.request_body,
job.job_name, u.id AS user_id, u.role, u.email
FROM job
JOIN auth.users u ON u.id = job.user_id
WHERE job.job_name = job_group.job_name
AND job.user_id = job_group.user_id
AND job.state = 'pending'
AND job.locked_at IS NULL
AND (job.next_run_at IS NULL OR job.next_run_at <= now())
ORDER BY job.created_at
LIMIT available_slots
FOR UPDATE SKIP LOCKED
LOOP
-- Update the job to 'running' and set locked_at
UPDATE job
SET locked_at = now(),
state = 'running',
last_run_at = now(),
updated_at = now()
WHERE id = current_job.id;
-- Log the start of the job run
PERFORM public.log_job(current_job.id, 'job run started');
-- Execute the job using pg_net
PERFORM private.run_job(
current_job.id,
current_job.job_name,
current_job.request_body,
current_job.user_id,
current_job.role,
current_job.email
);
END LOOP;
END IF;
END LOOP;
END;
$$;
#Process jobs
This will check through pg_net's internal _http_response table for requests that have been annotated with the X-Job header.
From there, it matches up the X-Correlation-ID header to the corresponding job table entry, and decides whether the job was successful based on the HTTP status code returned.
CREATE OR REPLACE FUNCTION private.process_jobs()
RETURNS VOID
LANGUAGE plpgsql
SECURITY DEFINER
SET search_path = public, extensions
AS $$
DECLARE
response RECORD;
job_record RECORD;
normalized_headers JSONB;
BEGIN
FOR response IN
SELECT * FROM net._http_response
FOR UPDATE SKIP LOCKED -- Lock the response to prevent concurrent processing
LOOP
-- Normalize headers to lowercase
SELECT jsonb_object_agg(lower(key), value) INTO normalized_headers
FROM jsonb_each_text(response.headers);
IF normalized_headers ? 'x-job' THEN
-- Find and lock the corresponding job record
IF normalized_headers ? 'x-correlation-id' THEN
SELECT * INTO job_record
FROM job
WHERE id = (normalized_headers->>'x-correlation-id')::UUID
FOR UPDATE;
IF FOUND THEN
DELETE FROM net._http_response WHERE id = response.id;
IF response.status_code = 200
OR response.status_code = 201
OR response.status_code = 204 THEN
-- Success: Update job to 'completed'
UPDATE job
SET state = 'completed', locked_at = NULL, updated_at = now()
WHERE id = job_record.id;
-- Log the successful completion
PERFORM public.log_job(job_record.id,
'job run completed successfully');
ELSE
-- Failure: Handle retries or mark as failed
PERFORM private.fail_job_with_retry(job_record.id);
PERFORM public.log_job(job_record.id,
'job run failed and will be retried');
END IF;
END IF;
ELSE
RAISE LOG 'job run failed due to a missing X-Correlation-ID header. '
'This is a permanent failure and will not be retried.';
DELETE FROM net._http_response WHERE id = response.id;
END IF;
END IF;
END LOOP;
END;
$$;
#Logging
This is relatively barebones, and just tracks job starting/finishing.
CREATE OR REPLACE FUNCTION public.log_job(
_job_id UUID,
_log_message TEXT,
_log_level TEXT DEFAULT 'INFO'
)
RETURNS VOID
AS $$
BEGIN
INSERT INTO job_logs(job_id, log_message, log_level)
VALUES (_job_id, _log_message, _log_level);
END;
$$ LANGUAGE plpgsql;
#Handling failed jobs
Jobs fail, the system will handle failures with configurable retries, and reset jobs where the edge function never returned a status (due to resource limits, this can happen).
-- mark a job as failed, and queue for a retry
CREATE OR REPLACE FUNCTION private.fail_job_with_retry(
_job_id UUID
)
RETURNS VOID
SECURITY DEFINER
AS $$
DECLARE
_retries INT;
_max_retries INT;
BEGIN
-- Fetch the current retries and max_retries for the job
SELECT retries, max_retries INTO _retries, _max_retries
FROM job
WHERE id = _job_id;
IF _retries + 1 >= _max_retries THEN
-- Mark job as permanently failed
UPDATE job
SET state = 'failed', locked_at = NULL, updated_at = now()
WHERE id = _job_id;
ELSE
-- Increment retry count and schedule next retry
UPDATE job
SET retries = _retries + 1,
state = 'pending',
-- Exponential backoff
next_run_at = now() + INTERVAL '5 minutes' * (2 ^ _retries),
locked_at = NULL,
updated_at = now()
WHERE id = _job_id;
END IF;
END;
$$ LANGUAGE plpgsql;
-- When a job has expired, reset its status to pending
CREATE OR REPLACE FUNCTION private.reset_stuck_jobs(
_timeout INTERVAL DEFAULT '15 minutes'
)
RETURNS VOID
SECURITY DEFINER
AS $$
BEGIN
UPDATE job
SET locked_at = NULL, state = 'pending', updated_at = now()
WHERE locked_at < now() - _timeout
AND state = 'running';
END;
$$ LANGUAGE plpgsql;
#pg_cron
With pg_cron enabled, you can configure the management functions to execute on a schedule that suits your workloads.
Below I've chosen to run the jobs very frequently because I wanted a relatively high throughput, but it can be tweaked to your preferences. One thing though: I would try to have run-jobs and process-jobs run out of sync with each other. You don't really want the job that picks up work running at the exact same time as the job that determines whether the work is completed, as it might introduce delays.
SELECT cron.schedule(
'run-jobs',
'20 seconds',
$$
SELECT private.run_jobs();
$$
);
SELECT cron.schedule(
'process-jobs',
'6 seconds',
$$
SELECT private.process_jobs();
$$
);
SELECT cron.schedule(
'reset-stuck-jobs',
'*/8 * * * *',
$$
SELECT private.reset_stuck_job_runs('8 minutes');
$$
);
#Edge functions
This is a barebones edge function that contains only the logic required to successfully process a job.
The important thing is that it responds in a way that the management functions can process. In the Postgres functions above, this means accepting and responding with specific headers to identify the request as coming from the job runner, and returning HTTP status codes to indicate whether the job was successful or not.
import "@supabase/edge-runtime";
import { createClient } from "@supabase/supabase-js";
Deno.serve(async (req) => {
const { data } = await req.json();
// X-Job and X-Correlation-ID are used as part of the Job Runner system.
const correlationId = req.headers.get("X-Correlation-ID");
const isJob = req.headers.get("X-Job");
if (!correlationId || !isJob) {
console.error("Missing required Job Runner headers");
return new Response(
JSON.stringify({
error: "Missing required Job Runner headers",
}),
{
status: 400,
headers: { "Content-Type": "application/json" },
},
);
}
console.log("X-Correlation-ID: ", correlationId);
console.log("X-Job", isJob);
const authHeader = req.headers.get("Authorization")!;
const supabase = createClient<Database>(
Deno.env.get("SUPABASE_URL") ?? "",
Deno.env.get("SUPABASE_ANON_KEY") ?? "",
{ global: { headers: { Authorization: authHeader } } },
);
const token = authHeader.replace("Bearer ", "");
const {
data: { user },
} = await supabase.auth.getUser(token);
/**
* Only run if we have a user context
*/
if (!user?.email) {
console.error("No valid user token received");
return new Response(
JSON.stringify({
error: "Unauthorized",
}),
{
status: 401,
headers: {
"Content-Type": "application/json",
"X-Correlation-ID": correlationId,
"X-Job": isJob,
},
},
);
}
// This is about where the rest of your worker logic will go.
const success = !!data;
if (success) {
console.log("Successfully processed request");
return new Response(null, {
status: 204,
headers: {
"Content-Type": "application/json",
"X-Correlation-ID": correlationId,
"X-Job": isJob,
},
});
}
console.error("Failed to process request");
return new Response(null, {
status: 500,
headers: {
"Content-Type": "application/json",
"X-Correlation-ID": correlationId,
"X-Job": isJob,
},
});
});
#Caveats
For me, this has worked best for tasks that are mostly I/O-bound – API calls, reading from the database, saving to the database, transforming JSON. Supabase Edge Functions have a few limits, but working around the two second CPU time one is particularly awkward. Forget running ML tasks, and decompressing a large-ish file won't work either.
The good news is that it seems Supabase will be adding flexibility there in 2025:
We have a very exciting roadmap planned for 2025. One of the main priorities is to provide customizable compute limits (memory, CPU, and execution duration). We will soon announce an update on it.
– Supabase blog
In the mean time it is prudent to break jobs up into discrete units of work. For example, instead of a single job that does a given task for all users, create a "router" task that queues up the task for each user.
There's plenty of ways you can extend this – I never added recurring jobs, for example, but I don't think it would be too tricky. You might also not like other decisions I made, like wiring the job names directly to the functions, but that is an intentional choice on my part to try and ensure the functions didn't end up too large.
Most importantly, this is a system that worked for me. A a job system goes, it is, shall we say... no frills. But it might be interesting to some others.
There is currently no comments system. If you'd like to share an opinion either with me or about this post, please feel free to do so with me either via email (ross@duggan.ie) on Mastodon (@duggan@mastodon.ie) or even on Hacker News.
Corrections and suggestions also welcome, you might prefer to use the accompanying Github repository if so.